
[Paper Review] Faithfulness-Aware Decoding Strategies for Abstractive Summarization (EACL 2023)
Published:
Faithfulness 향상을 위한 디코딩 전략
Abstract
Abstractive summarization는 본문의 단어를 그대로 요약문에 포함시키는 것이 아니라, 요약문에 적합한 단어들을 사용하여 요약문을 생성하기 때문에 요약문에 대한 faithfulness를 평가하는 것이 중요하다. 일반적으로 언어 생성을 할 때, beam search 혹은 sampling을 주로 사용하게 되는데, 디코딩 전략에 따라 faithfulness가 어떻게 변화하는 지에 대한 분석이 부족하다. 따라서, 해당 논문에서는 디코딩 전략에 따른 faithfulness 변화에 대한 분석과 beam search 대신 faithfulness 평가를 디코딩 랭킹에 직접 반영하는 방법과 lookahead 휴리스틱을 통해 미래 예측 요약문의 faithfulness 점수를 반영하는 방법을 제안한다.
Introduction
Pre-trained language model이 많이 발전했음에도 불구하고, 생성한 요약문에 본문에 없는 잘못된 내용 혹은 객체가 포함되는 할루시네이션과 같은 문제가 발생한다. 이러한 문제를 해결하기 위해서 post-processing이나 faithfulness-aware 학습 방법들이 제안되었다. 하지만, 디코딩 전략만으로 faithfulness를 조절하는 연구는 아직 탐험되지 않았다. 따라서, 해당 논문에서는 대표적인 디코딩 전략인 greedy decoding, beam search, nucleus sampling이 faithfulness에 어떠한 영향을 미치는 지 분석한다. 또한 faithfulness-aware 디코딩 전략 2개를 제안한다. 먼저, faithfulness 평가를 weighted combination한 점수를 반영한 re-rank 방법과 lookahead heuristic을 사용하여 미래 요약문이 높은 점수를 낼 수 있을 법한 요약문을 생성하는 방법을 제안한다. 새롭게 제안하는 디코딩 전략의 높은 computational cost를 극복하기 위해 distilation을 사용한다.
Method

대표적인 디코딩 전략인 beam search나 sampling의 경우 faithfulness를 직접적으로 반영할 수 없다. 따라서, faithful한 path를 탐험하기 위한 re-ranking 방법과 faithfulness heuristic을 반영한 lookahead 디코딩 전략을 제안한다. 먼저 faithfulness를 활용한 re-ranking을 진행했을 때, 기존에 낮은 확률로 생성되었을 요약문이 높은 faithfulness를 통해 top rank가 된다. Re-ranking에 사용하는 faithfulness 평가 지표 경우, FactCC, BS-Fact, DAE, QuestEval 등의 faithfulness 평가 지표들을 사람이 평가한 수치인 FACTCOLLECT와의 linear regression을 진행하여 각 지표에 weight을 부여한다.
기존의 lookahead를 활용하여 제약 조건을 만족하는 지 미리 예측하는 연구를 faithfulness 예측에 활용한다. 요약문의 faithfulness를 예측하기 위해서 정답이 필요없는 reference-free 지표인 BS-Fact를 사용한다. 위의 figure에서 보이듯이 Lookahead를 사용하면 굉장히 큰 후보군 중에 선택하게 되면, 원래 더 높은 확률(0.8)의 hallucination이 포함된 요약문을 선택하지 않고 낮은 확률(0.6)의 faithful한 요약문을 생성할 수 있다. 요약문의 각 토큰을 선택하는 방법은 다음과 같다.
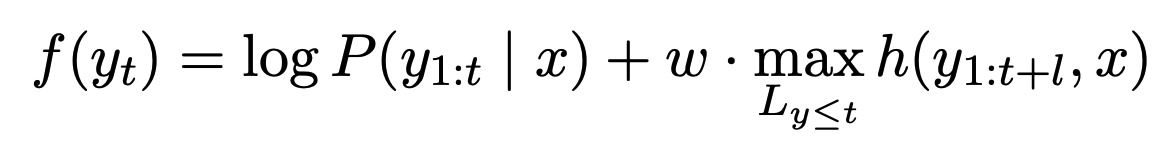
$logP$는 모델의 점수를 의미하고, $h(.)$은 reference-free faithfulness 평가 지표를 의미한다. $l$은 미래에 봐야할 토큰의 수를 의미하며, 길이를 명시할 수 있지만 전체 요약문을 사용한다.
하지만, 제안된 디코딩 방법들의 경우 디코딩 과정 중에 높은 computational cost가 필요하다.따라서, distilation을 활용하여 student 모델이 greedy decoding만으로 faithful한 요약문을 생성할 수 있도록 한다. 여기서 사용하는 distilation의 목적은 모델의 크기를 줄이는 것이 아니라 디코딩 시간을 개선하고자 함이다. 일반적인 distilation의 경우 teacher 모델의 확률 분포를 student 모델이 imitate하는 것이 목표이지만 decoding 전략에 상관 없이 확률 분포가 동일하기 때문에 새로운 distilation loss를 제안한다. 해당 논문에서는 정답 요약문과의 크로스 엔트로피에 teacher 모델의 요약문과의 크로스 엔트로피를 보간하여 학습 loss를 제안한다.
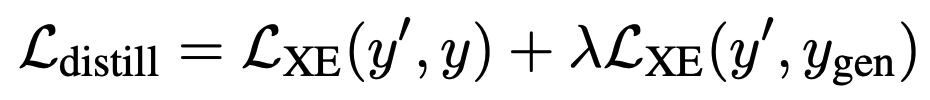
$y’$은 생성한 student 모델이 생성한 요약문, $y$는 정답 요약문, 그리고 $y_{gen}$은 teacher 모델이 생성한 요약문을 의미한다.
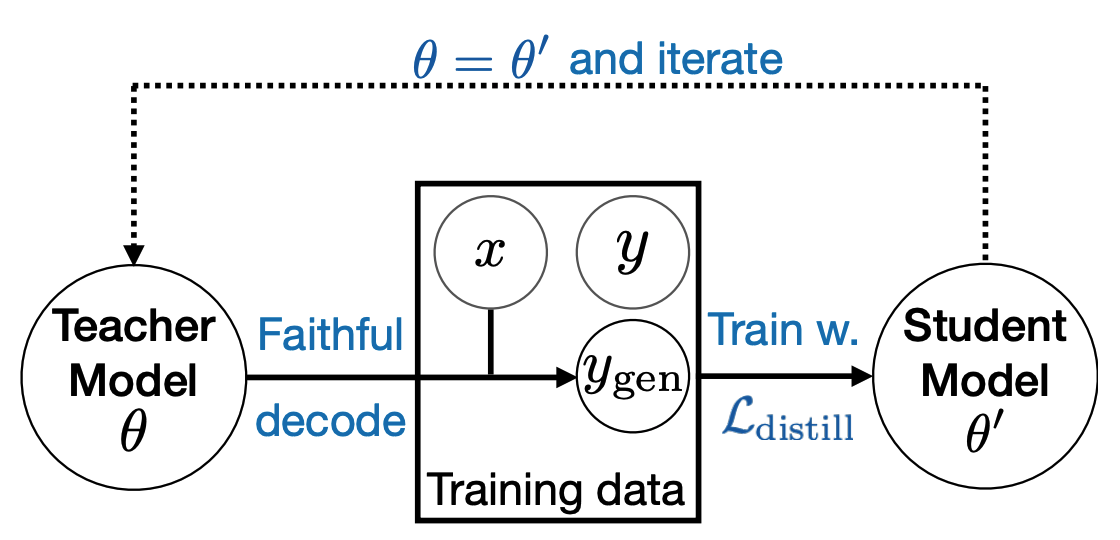
Distilation 후에 student 모델은 greedy decoding을 사용하기 때문에, decoding 속도를 향상시키기 위해서 iterative distilation을 사용한다. Student 모델이 faithfulness-aware decoding을 통해 성능이 향상되면, 해당 모델을 teacher 모델로 재사용하여 새로운 student 모델에게 더 faithful한 knowledge를 제공한다.
Experiments
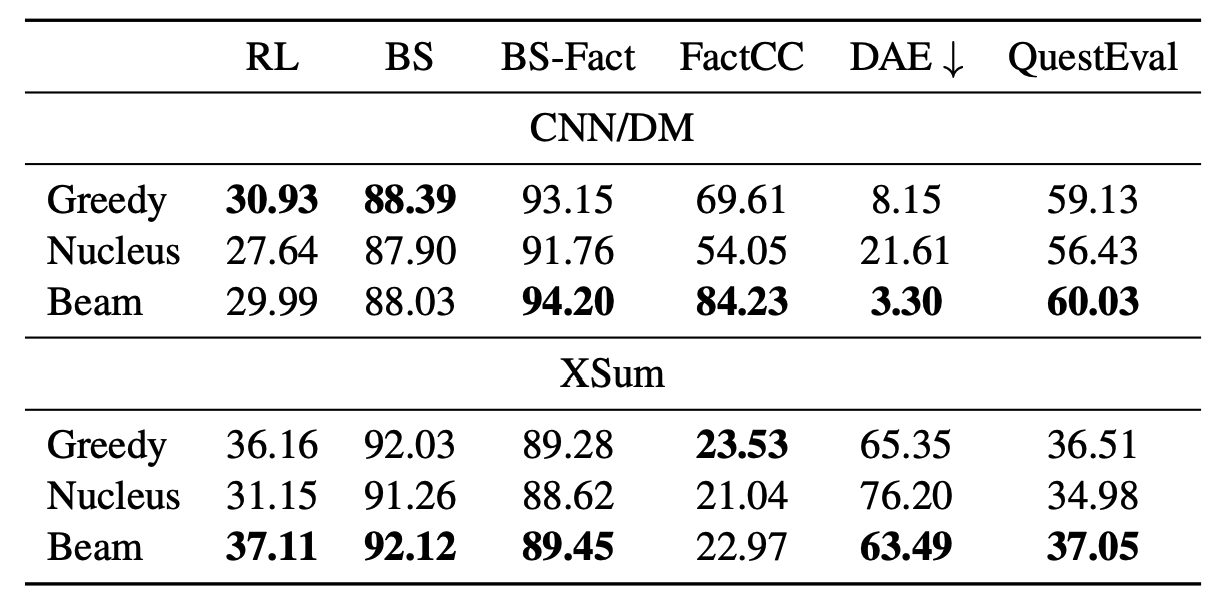
평가는 요약 태스크에서 주로 사용하는 CNN/DM 데이터셋과 XSum 데이터셋을 사용하였다. 평가 지표로 ROUGE-L(RL), BERTScore의 F1(BS), BERTScore의 precision(BS-Fact), FactCC, DAE, QuestEval을 사용하여 평가하였다. 위의 표에서 보이듯이 모든 지표에서 좋은 디코딩 전략은 없었으며, 대부분 beam search를 할 때, 좋은 점수를 보였다. Nucleus sampling은 랜덤한 특징으로 인해 greedy search와 비교해서, faithfulness에서는 도움을 주지 못했다.
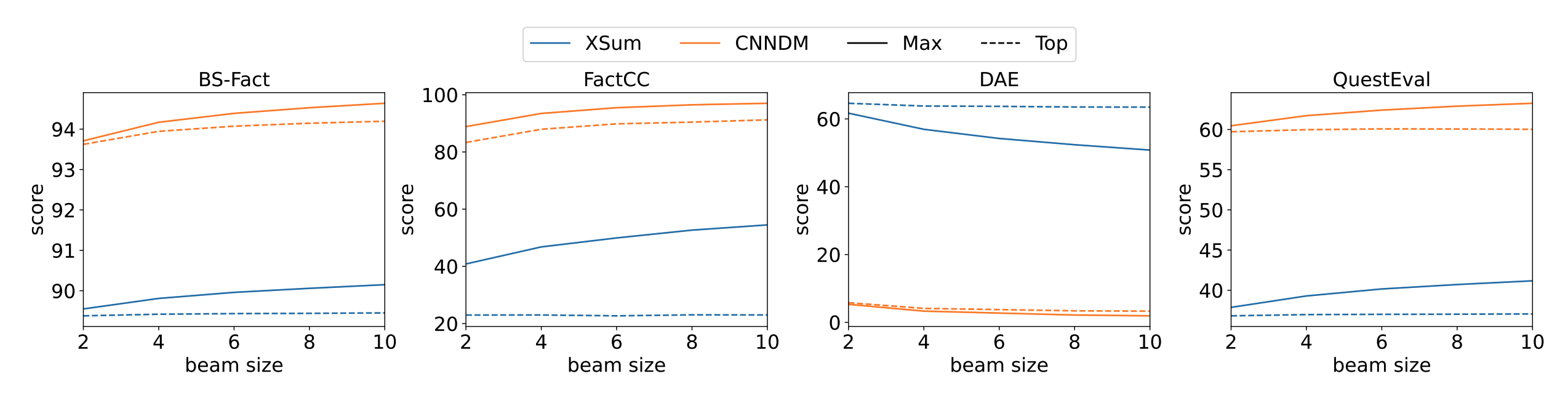
모든 지표에서 beam의 크기가 커질수록 faithfulness 향상에 도움을 주었다. 이 결과를 통해, search space가 커질수록 exploration이 커지며, 이것이 곧 faithfulness 향상에 도움을 준 것을 알 수 있었다. 따라서, 해당 논문에서 제안하는 re-ranking 전략의 잠재력을 확인할 수 있다.
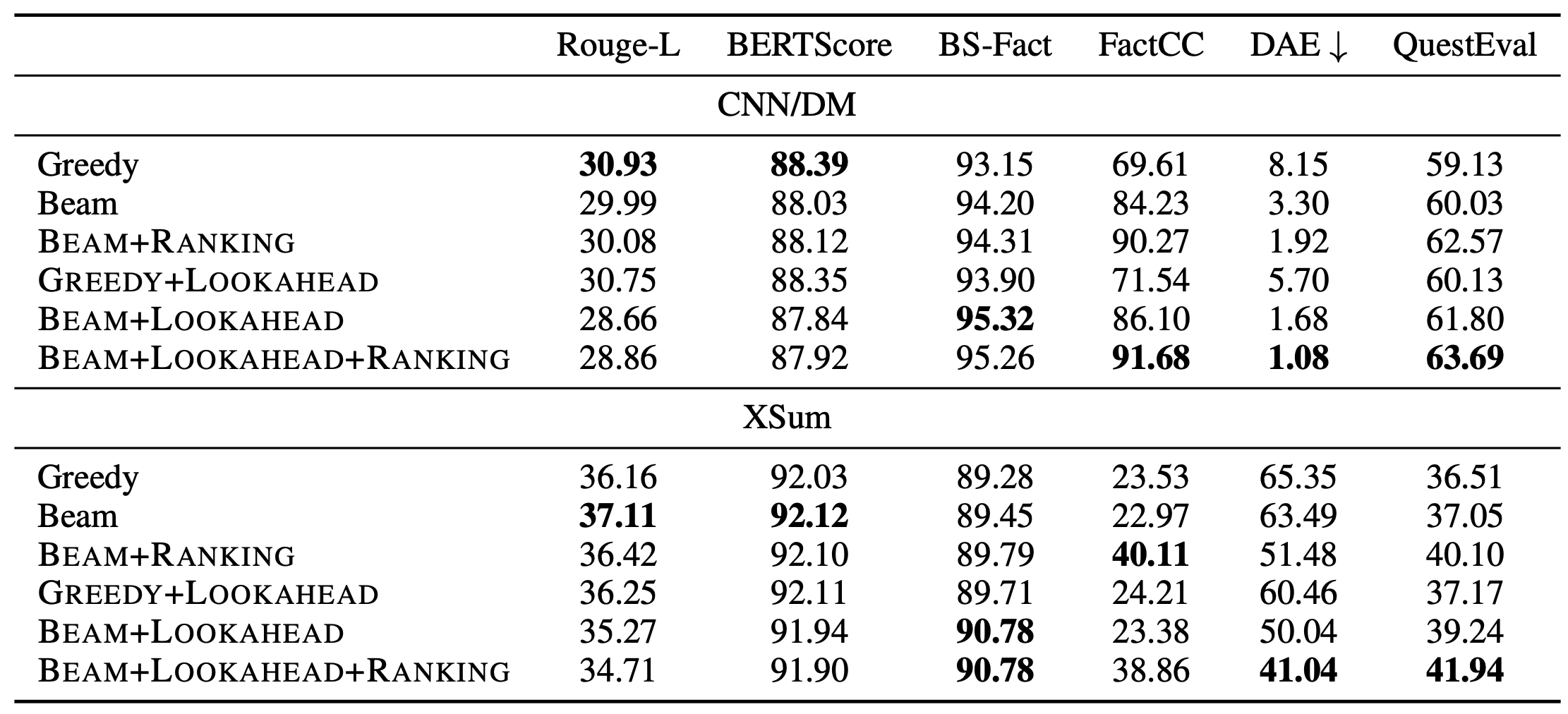
위의 테이블을 보면, 해당 논문에서 제안하는 디코딩 전략들의 성능을 확인할 수 있다. 눈에 띄는 것은 faithful 디코딩 전략을 사용할수록 ROUGE-L 점수가 하락했다는 것인데, 이러한 faithfulness와 ROUGE-L 간의 trade-off는 이전의 연구들에서 확인된 바 있다. 또한 정답 요약문의 70%가 할루시네이션을 갖고 있기 때문에, ROUGE 점수가 하락했다는 것이 큰 의미를 갖지 않는다. 그 외의 평가 지표들에서는 해당 논문에서 제안하는 faithful 디코딩의 효과를 볼 수 있다.
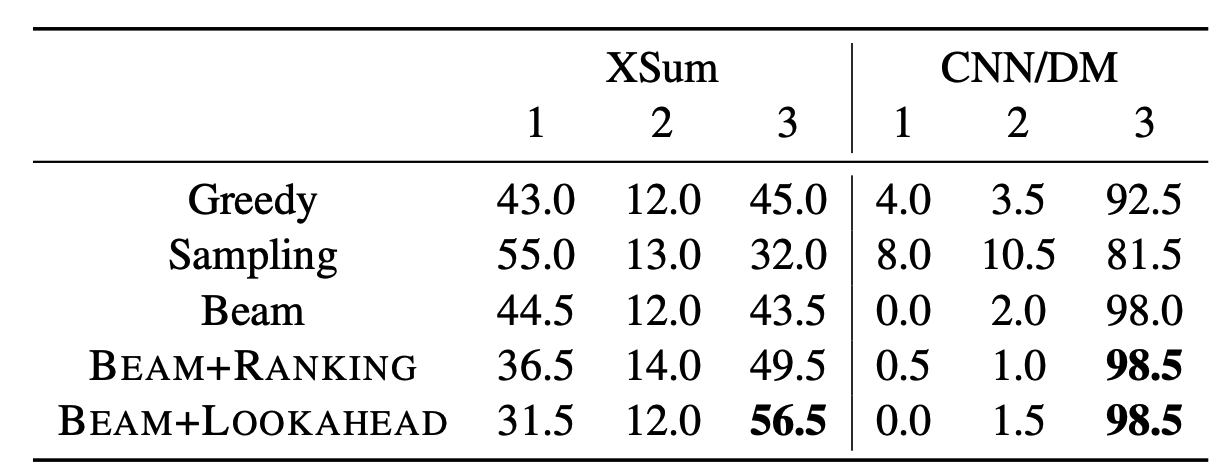
더 정밀한 평가를 위해 human evaluation을 진행했다. Sampling은 자동 평가 지표와 동일하게 가장 낮은 점수를 보였지만, 흥미롭게도 beam search보다 greedy search가 더 faithful 하다고 평가되었다. 또한 해당 논문에서 제안하는 re-ranking 방법과 lookahead 방법을 사용했을 때, faithfulness가 크게 향상된 것을 볼 수 있다.
Analysis
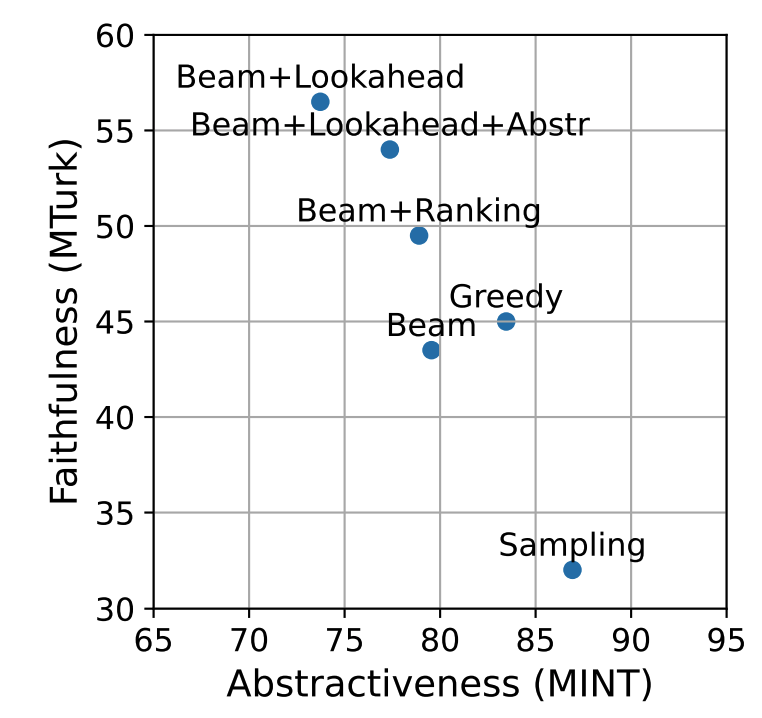
더 faithful해지면, 더 extractive해질 수 있다는 기존 연구에 따라, 해당 논문에서도 faithfuness와 abstractiveness의 trade-off를 분석하였다. 위의 figure를 보면 기존의 연구와 유사하게, abstractiness가 작아질수록 faithfulness가 커지는 것을 볼 수 있다. 하지만, abstractiveness가 줄어든 양에 비해, faithfulness가 향상된 양이 더 크기 때문에, 해당 논문의 방법론이 의미가 있다고 주장한다. 또한, lookahead의 경우 다양한 variation이 가능하기 때문에, 위의 figure에 있는 $Beam+Lookahead+Abstr$처럼 사용할 수 있다.
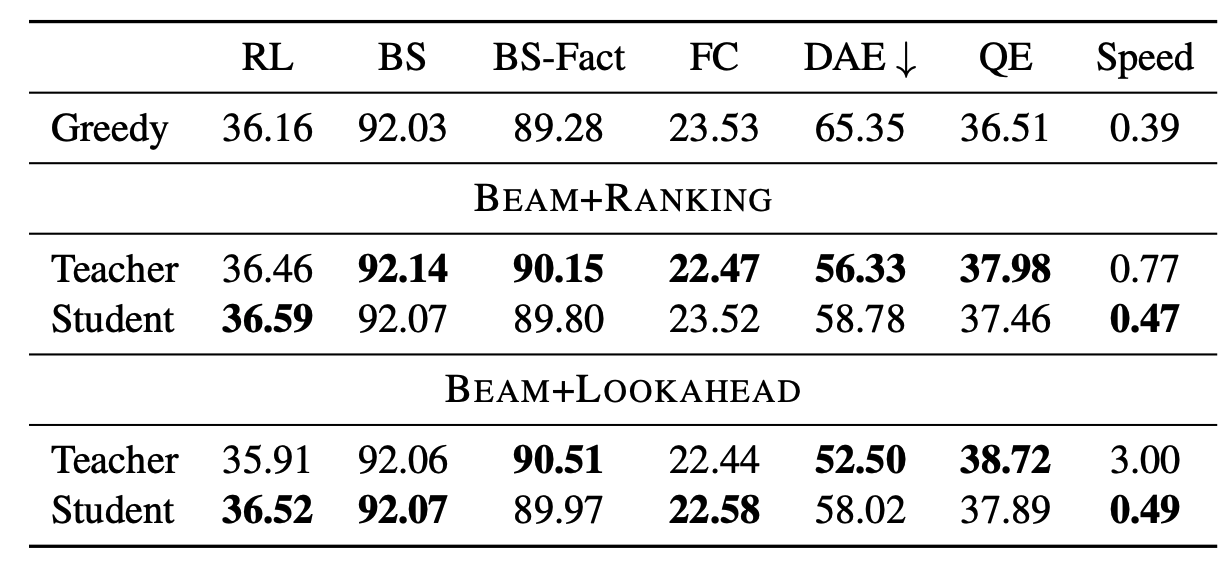
위의 표에 따르면, student 모델이 teacher 모델에 비견할만한 점수를 보임에도 디코딩 속도는 더 빠른 것을 볼 수 있다.
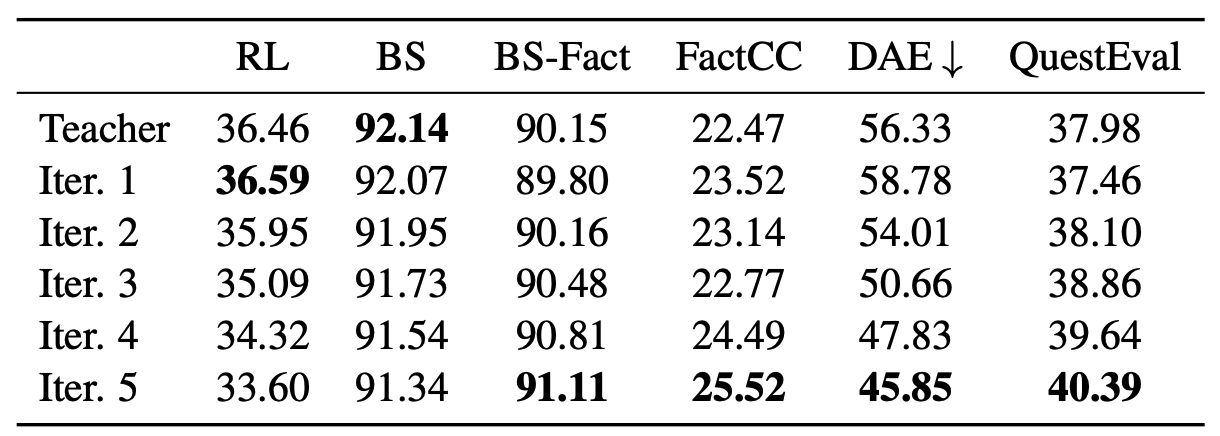
위의 표에 따르면 iterative distilation의 횟수가 많아질 수록 더 faithful한 요약문을 생성한다고 한다.
Conclusion
디코딩 전략에 따라 faithfulness를 평가할 수 있다는 점이 흥미로웠다. 또한, 다양한 평가 지표들을 linear combination하여 활용하는 점이, 요약 태스크 뿐만 아니라 다양하게 활용될 수 있을 것 같았다. Human evaluation에서는 꽤 높은 성능 향상을 보였지만 여러 자동 평가 지표에서는 큰 성능 향상이 없는 것이 아쉬웠다. 하지만, ROUGE-L 점수 처럼 하락한 지표들도 솔직하게 작성한 것이 인상 깊었다.